
Fujitsu uses AI to discover characteristic causal relationships of individual data in medicine, marketing, and more
In a recent trial demonstration, Fujitsu’s researchers succeeded in rediscovering the gene of interest in the colorectal cancer classification, offering a key to the development of a treatment plan individualised for each patient
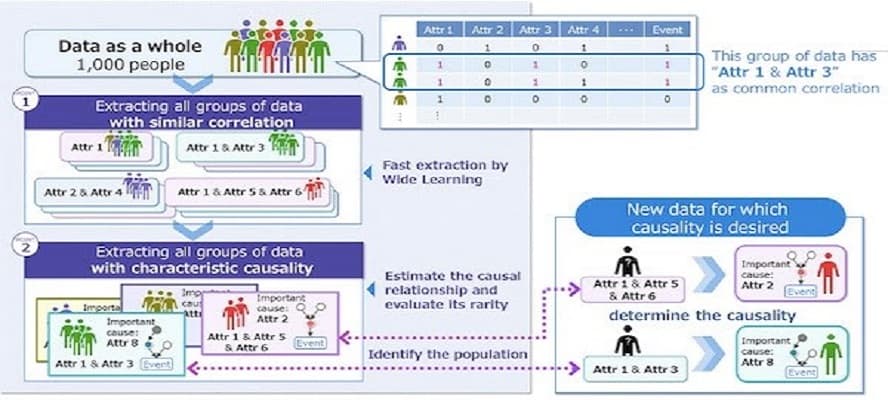
Fujitsu has developed a technology to discover the characteristic causality of individual pieces of data by quickly extracting all the groups of data that have a common correlation from an entire dataset, and evaluating the causality of each group of data to find the characteristic causality. The technology specifically addresses the need to isolate and identify characteristics from data in different real-world scenarios.
In the medical field, for example, it is necessary to identify the characteristic genes that affect the development of cancer in individual patients. In the field of marketing, sales representatives need to find the characteristic factors that lead individual customers to make a purchase.
In a recent trial demonstration, Fujitsu reportedly applied the technology to the gene expression data of colorectal cancer patients, estimating the characteristic causal relationship that appears in the data of each patient. Fujitsu’s researchers succeeded in rediscovering the gene of interest in the colorectal cancer classification, offering a key to the development of a treatment plan individualised for each patient.
In addition to medical care and marketing, this technology enables use cases including customer credit scoring in finance and identification of the cause of product defects in manufacturing.
As per a company release, Fujitsu will continue to conduct research in the field of genomic medicine with the aim of contributing to medical research, including in the field of personalised medicine, as well as to shed light on the causes of cancer. In FY 2020 ending in March 2021, Fujitsu will also apply the new machine learning technology to demonstrate its utility in various fields, including marketing, manufacturing, and finance, in addition to the medical field. Fujitsu aims to put the technology into practical use in FY 2021.
Background
While the use of AI to tackle real-world problems continues to accelerate, certain challenges remain in applying AI and machine learning technologies to resolve challenges in a variety of fields, including medicine and marketing. To identify the key drivers of the problem to be solved and develop a strategy, for instance, it’s necessary to not only look at the correlation between attributes A and B, but also at the causal relationship between A and B, such as “A is the cause of B.”
To date, data analysis research has led to the development of techniques for estimating the common cause-and-effect relationship of data. In addition, estimating the characteristic cause-and-effect relationship of each piece of data is needed to solve many real problems.
For example, in the case of cancer treatment in the medical field, many cancer patients have been identified by the expression of unique genes that affect the disease state of cancer. In order to devise an appropriate treatment plan for individual patients, therefore, doctors must identify genes that are unique to each cancer patient, not genes that are common to all cancer patients.
In the case of promotions in marketing, each customer within a larger group has a distinctive characteristic that leads to their purchase, and in order to plan appropriate outreach for individual customers, it becomes necessary to identify a characteristic, motivational cause for each customer, not a cause common to all customers.
In this way, there has been a need for new techniques for estimating the characteristic cause-and-effect relationship of each piece of data to solve many real problems.
Issues
In order to accurately estimate the characteristic cause-and-effect relationship for each data item, researchers must compare the results of different operations and actions applied to the corresponding person or object under the same conditions.
However, it is difficult to obtain, for example, the results of differing gene expression in a single cancer patient or implementing different promotion measures for one customer. Therefore, the challenge was how to discover the characteristic causality of each piece of data from the entire data of various patients and customers.
Newly developed technology
Fujitsu has succeeded in developing a new cause-and-effect search technology that can discover the characteristic cause-and-effect relationships of individual data items. The features of the developed technology are as follows.
1. Technique for extracting all groups of data with similar correlation
Focusing on correlations, which are less severe than causality, all groups of data with a common correlation from the entire data are extracted. When the number of data attributes exceeds 50, the maximum number of possible correlations exceeds 1,000 trillion1. However, by using Fujitsu’s “Wide Learning”2 technology, which finds all important combinations without omission, it is possible to discover any correlation in the data and to extract all such groups of data in seconds.
For example, to determine the causes that contribute to the development of cancer, a group of patients with a common correlation is extracted by searching for combinations of expressed genes, with the presence or absence of gene expression as an attribute.
2. Technique for extracting all groups of data with characteristic causality
Next, causality for the population of data is estimated and the attributes in each causality compared, as well as the strength of the causality, and the direction of the causality. This makes it possible to quantitatively evaluate the rarity of causality and to comprehensively discover those with high rarity scores as characteristic causality. Because these two techniques can extract all populations of data with characteristic causality, it is possible to determine the characteristic causality of each data by identifying the population that corresponds to the new data for which causality is desired.
Outcome
Previous genetic analysis studies have shown that there are several types of colorectal cancer, including those with a strong immune response and those with metabolic abnormalities, in addition to the conventionally-known common types, and that each type expresses a different gene.
With the cooperation of Professor Kenzo Takahashi, Assistant Professor Takuya Miyagi, and Assistant Professor Daisuke Utsumi, of Graduate School of Medicine, University of the Ryukyus3, researchers from Fujitsu Laboratories extracted gene expression data4 from approximately 1,000 colorectal cancer tissues and normal colorectal tissues from data published by The Cancer Genome Atlas (TCGA,5) and GTEx6, and applied this technology to the extracted data to confirm that the genes important in distinguishing the types of colorectal cancer7 can be identified automatically.
Professor Kenzo Takahashi commented, “This technology provides medical researchers with feedback, including the causal relationship that provides a concrete basis for the discovery, and enables the identification of carcinogenic factors in each patient. We hope that this technology will lead to the provision of optimal medical care for each, individual patient.”
References
(1) When the number of data attributes exceeds 50, the maximum number of possible correlations exceeds 1,000 trillion There are at least two classifications per attribute (such as “Yes” “No” for gene expression), and when 2 is raised to the power of 50, there are more than 1,000 trillion correlations.
(2) Wide Learning Technology AI technology that can explain reasoning and discover knowledge by exhaustive listing of hypotheses: Fujitsu’s New AI Technology “Wide Learning” Enables Highly Precise Learning Even from Imbalanced Data Sets (September 19, 2018 Press Releases, https://bit.ly/37raqTu)
(3) University of the Ryukyus Location: Nishihara-cho, Nakagami-gun, Okinawa Prefecture; President: Mutsumi Nishida.
(4) Gene expression data For the purpose of this verification trial, the Department of Dermatology, School of Medicine, University of the Ryukyus independently created data based on the criteria for high and low expression levels of each gene.
(5) TCGA The Cancer Genome Atlas. A joint project between the National Cancer Institute (NCI) and the National Human Genome Research Institute (NHGRI) (https://bit.ly/3mkZ1ss). In the experiment, TCGA will use data on gene expression levels in samples from 33 different types of cancer.
(6) GTEx An international consortium (https://www.gtexportal.org/home/) consisting of several research institutions, including the US Broad Institute. In this experiment, data on gene expression levels in human body tissues released by GTEx was utilised.
(7) Colorectal cancer type: The classification of colorectal cancer at an international conference in the US and Europe in 2015. (https://bit.ly/2KrXFPj)